Abstract
Automatically generating multiview illusions is a compelling challenge, where a single piece of visual content offers distinct interpretations from different viewing perspectives. Traditional methods, such as shadow art and wire art, create interesting 3D illusions but are limited to simple visual outputs (i.e., figure-ground or line drawing), restricting their artistic expressiveness and practical versatility. Recent diffusion-based illusion generation methods can generate more intricate designs but are confined to 2D images. In this work, we present a simple yet effective approach for creating 3D multiview illusions based on user-provided text prompts or images. Our method leverages a pre-trained text-to-image diffusion model to optimize the textures and geometry of neural 3D representations through differentiable rendering. When viewed from multiple angles, this produces different interpretations. We develop several techniques to improve the quality of the generated 3D multiview illusions. We demonstrate the effectiveness of our approach through extensive experiments and showcase illusion generation with diverse 3D forms.
Overview ↑ back to top
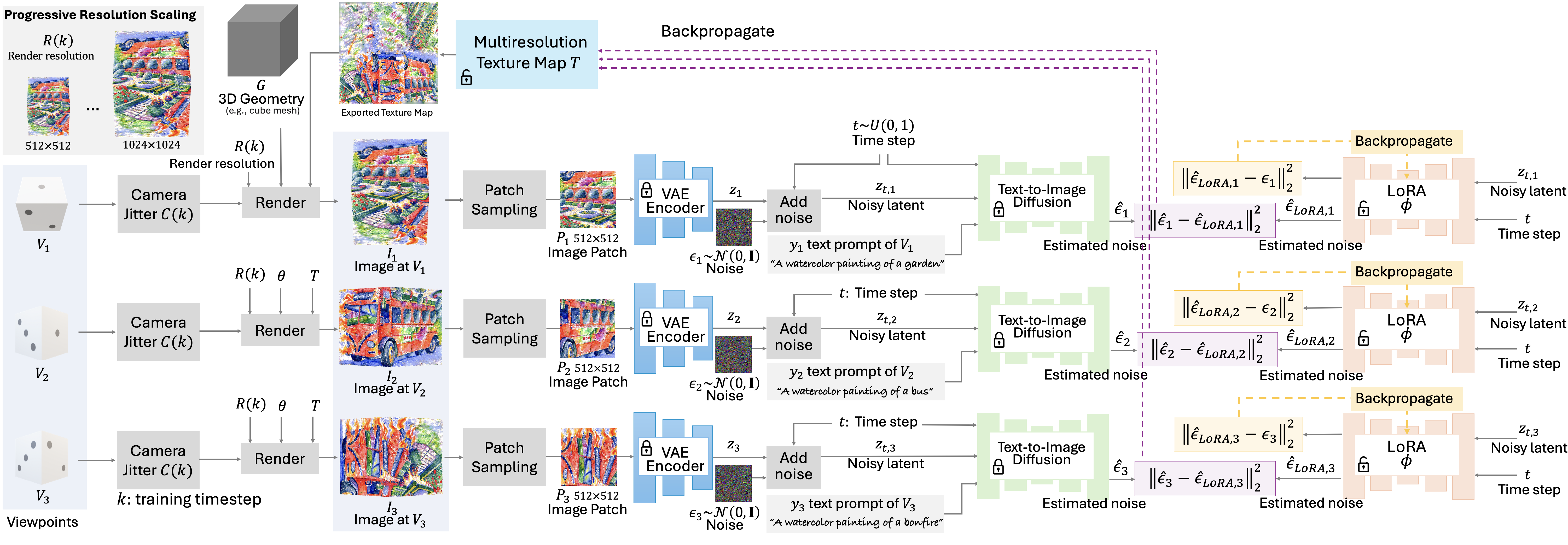
Given multiple text prompts, we aim to create 3D illusions with multiple interpretations, each respecting the corresponding text prompt. We achieve this by selecting viewing angles of common 3D shapes or reflective surfaces with overlapping regions and optimizing them to align with the text descriptions. Our method leverages the power of diffusion models and incorporates several techniques and design choices to enhance the quality of these 3D multiview illusions.